VPCエンドポイントについてまとめてみた。
こんにちは!たいきゅんです!
今回はVPCエンドポイントについて簡単にまとめてみようと思います。
VPCエンドポイントとは
VPCエンドポイントはVPCとサポートされているサービスの間のプライベート通信を有効にするためのエンドポイントのことです。セキュリティの問題でインターネットに接続せずにサービスを繋げたい時に使用します。
インターフェイスエンドポイント・ゲートウェイエンドポイント・ゲートウェイロードバランサーエンドポイントの三種類が存在します。
インターフェイスエンドポイント
一部AWSサービスやNLBを介した独自サービス、サポートされているAWS Marketplaceサービスにプライベート接続するためのエンドポイントです。作成するとVPC内にプライベートアドレスを持つENIが作成されます。
ゲートウェイエンドポイント
s3およびDynamoDBへのアクセスをプライベートに接続することができます。
VPCエンドポイントは作成されないが、サービス利用側のルートテーブルにエンドポイントのルーティングを設定します。
ゲートウェイロードバランサーのエンドポイント
ゲートウェイロードバランサーを介してサービスにプライベート接続するためのエンドポイント。VPC内にプライベートアドレスを持つENIが作成されます。
VPCエンドポイントのメリット
1.インターネットゲートウェイが不要
インターネットとの出入り口を作成せずとも外部サービスと通信することができます。通信をプライベートに実行したい時に使用します。
2. NATゲートウェイが不要に
NATゲートウェイなしでインターネットに出られる構成を作ることが可能になります。
3. セキュリティーグループによる制限
VPCエンドポイント作成時にはセキュリティグループも同時に作成するため、インバウンド、アウトバウンドルールを使用して通信を制限できます。
利用例
1.AWS Session Maneger用のエンドポイント作成
セッションマネージャーを使ってプライベートサブネット内にあるEC2インスタンスにSSHしたい場合にVPCエンドポイントが使えます。
インターネットゲートウェイ・NATゲートウェイなしでSSHできるので便利です。
2. ECRのイメージをpull
ECSをプライベートサブネットで作成する場合、ECRからイメージをpullするためインターネット通信が必要になります。こちらをプライベートに実行するためにVPCエンドポイントが利用できます。
AWS内での通信で事足りるのでセキュアな環境が作成できます。
今回はVPCエンドポイントについてまとめてみました。VPCは作ったことがあってもVPCエンドポイントまで作成したり考えたことが無かったのでとても勉強になりました!
SSMを使ってプライベートサブネットのEC2インスタンスにSSHするハンズオンをやればなんとなくイメージが湧くと思いますので是非やってみて欲しいです。
最後まで読んで頂きありがとうございました!
GitHubActionsに入門してみた
今回はCI・CDパイプラインのシェアが非常に高いGitHubActionsの入門編です。
未経験転職でもCI・CDパイプラインの構築は今は必須となりつつあり、そのファーストチョイスにもなってきていると思います。
そんなGitHubActionsの基本について今回まとめていこうと思います。
CI・CDとは
CI・CDは(Continuous Integration・Continuous Delivery)、日本語では継続的インティグレーション・継続的デリバリーと訳されます。
継続的インティグレーションは、主にソフトウェア開発の自動化を指します。例えば、テストコードが正常に完了するか毎回手動で確認する場合多くのコストがかかります。これを自動化することで開発者の負担の軽減やヒューマンエラーの回避等が期待できるといった次第です。
継続的デリバリーはアプリケーションの自動デプロイを指します。アプリケーションを高頻度でデプロイすることが求められる現在のアプリケーション開発において継続的デリバリーは欠かせません。例えば「コードをbuildしてECSにデプロイする」作業を手動実行するとこちらも開発者の負担の軽減やヒューマンエラーのリスクがありますが、これをソフトウェアに任せることでリスクを避け、開発者がより開発に時間を割けるようにすることが期待できます。
GitHub Actionsとは
GitHub ActionsはCI・CDパイプライン構築のためのソフトウェアの一種です。
GitHubによって開発されており、publicリポジトリで使用する場合は無料で使用できるのが嬉しい点です。
またドキュメント整備も進められており、日本語表示が自動的にできるのも嬉しい点です。
公式ドキュメント
github.co.jp
GitHub Actionsのメリット
1. ドキュメントの豊富さ&日本語対応
ドキュメント整備が進んでいているのがメリットの一つです。
また日本語対応が標準で、表現も個人的にはAWSのドキュメントより分かりやすいと感じるのもいい点です。
未経験の方・私みたいにまだ経験の浅い人は公式ドキュメントを敬遠しがちなイメージがありますが、公式ドキュメントを読むことが理解するための最短ルートでもあったりします。またそれが難しいため嫌になってしまうことがあるあるかなと思いますがGitHub Actionsのドキュメントは一味違う気がしてます。
是非一度GitHubActionsの公式ドキュメントを読んでみてください。
2. GUI?から簡単に作成できる
自動化と聞くと「コードたくさん書く必要がありそう」「初期学習コストがかかりそう」といったイメージを持つ方も多いと思います。(私もその一人です。)しかしGItHubActionはGitHubのページ上でポチポチするだけでファイルを生成してくれますし、公式ドキュメントに記載されているコードをそのまま貼り付ければ直ぐにCI・CDを試せる気軽さも魅力だなと感じております。
3. Gitとのシナジーが見込める
バージョン管理にGitを使用している企業が非常に多い今、そのGitで一緒にCI・CDもできるのは非常に効率よく感じます!よく使われるGitHubに付随するからこそメンテナンスや新規機能の開発も活発に行われているのも支持される理由の一つではと思います。
学習ロードマップ
1.公式ドキュメントを読む
繰り返しになりますが公式ドキュメントがとてもよくできていて理解する近道だと思いますので、まず公式ドキュメントを読んでGitHubActionsで使われる基礎用語の理解をしてもらえればと思います。
2. 実際に構築してみる
ある程度基礎を読んだら次には構築して動かしてみることをお勧めします。分からなかったらその都度公式ドキュメントを参照して理解を深めて頂きたいです。
私の場合は業務でいきなり作ってからのスタートだったので、トライ&エラーでまず動くものを作ってから用語の理解という流れでしたが、用語をある程度理解してからやったほうが早く深く理解できると思います!!
またCIから始める方が手軽でいいと思います。使用されてる言語・フレームワークでテスト実行コマンドがあると思いますので、それをGitHubActionsで自動実行できるように設定してみてください!
トリガーはご自由ですが、PR作成時が設定されやすいトリガーだとと思いますので参考にしてみてください。
CIができたらCDにも挑戦する流れがベストかと思います。CDを作成するとなると別途クラウドの知識が必要となりますし設定も必要です。
私自身コードビルドを使用してデプロイしたことがないので、今後挑戦できたらと考えております。
まとめ
今回はGitHubActionsの入門について簡単にまとめてみました。
今使えて損ない技術だと思うので是非挑戦してみて欲しいと思いますし、私もGitHubActionsを使って色々トライしたいと考えています。
別途LaravelのUnitTestをGitHubActionsで自動で走らせるハンズオンをまとめてみようと思います!
最後まで読んで頂きありがとうございました!
terraform基礎 -Dockerで環境構築とS3バケットを作成-
今回はterraformをDockerで環境構築し、簡単なS3バケットの操作を紹介したいと思います。
「Terraformに入門してみた」という記事も作成しておりますので、良ければ併せて読んでください。
taikyunn-blog.hatenablog.com
環境構築
まずは環境構築からです。
TerraformのDocker imageが公開されているためこちらを使用します。
一つのコンテナだけですが、楽なのでdocker-compose.ymlを使用しています。
docker-compose.yml
version: '3' services: terraform: container_name: terraform image: hashicorp/terraform:latest volumes: - .:/terraform - ~/.aws:/root/.aws working_dir: /terraform/terraform entrypoint: ash tty: true
TerraformでAWSのリソースを構築する場合、AWSへアクセスができるcredentials情報が必要となります。
今回は~/.aws 配下にcredentials情報が保存されていることを前提として作成しました。
もしご自身のPCのAWS credentialsが別のフォルダーに設定してある場合はそちらに適宜変更していただければと思います。
envファイルを使用してcredentialsを直書きしてgitignoreする方法もありますが、
もしものことがあるためこちらの方がいいかもしれません。
この状態で docker compose up -d --build をしていただくとコンテナが立ち上がるはずです。
S3バケットを作成しよう
S3バケットの作成に関してです。
基本的には公式Docの通りにコーディングすれば作成することができます。
Terraformはバージョンアップするごとに記法が変わったりするので、バージョン情報には注意してください。
公式Doc
registry.terraform.io
main.tfを作成
Terraformを作成する上ではmain.tfファイルが必要でないとエラーになるので注意してください。
main.tfはterraform/terraformフォルダ内に作成してください。
main.tf
# AWSを使用する宣言 provider "aws" { region = "ap-northeast-1" } resource "aws_s3_bucket" "b" { bucket = "test-bucket" acl = "private" # バージョニング設定 versioning { enabled = true } # デフォルトの暗号化 server_side_encryption_configuration { rule { apply_server_side_encryption_by_default { sse_algorithm = "AES256" } } } }
こちらがterraformの初期設定とS3バケットの作成をするtfファイルです。
コメントを記載していますが、詳細は公式Docを参照してください。
リソースの作成
ファイルが作成できたら、terraformを使用するためのセットアップコマンドを実行します。
docker compose exec terraform terraform init
こちらが正常に実行されると自動生成ファイルが作成されます。
次にterraform planを実行し、terraformが実行できるかチェックします。
docker compose exec terraform terraform plan
文法エラーがある場合はエラーが表示されますが、ない場合は下記のように表示されるはずです。
Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run "terraform apply" now.
上記が表示されたらあとは構築するのみですが、、コードの整形を行ってからにしましょう。
// 整形 docker compose exec terraform terraform fmt // リソースの作成 docker compose exec terraform terraform apply
リソースの破棄
terraform apply時実行確認がされると思いますので、yes と入力してください。
コマンドが完了すると、S3バケット(バケット名:test-bucket)が作成されるはずです。
リソースを廃棄したい場合は、terraform destroyコマンドを実行すれば自動的に廃棄されます。
// 整形
docker compose exec terraform terraform destroy
まとめ
私はterraformが初めて使用したIaCツールだったのですができた時思った以上に簡単でかつ少しプログラミングができるようになった気がして感動しました!
AWSで手動で構築していると裏側で自動的に構築してくれている時があると思いますが、IaCツールを使用することで自動構築してくれていた箇所を意識することが必要になりさらに理解が深まると思います。
使ったことない方は是非使ってリソース構築を簡単にして欲しいです。導入ハードルは思った以上に高くないと思います!
最後まで読んでいただきありがとうございました!
「誰も教えてくれなかったアジャイル開発」を読んでみた
今回は「誰も教えてくれなかったアジャイル開発」という本を読んだのでアウトプットしていきます。
この本を一言で言うと「アジャイル(以下AG)とは何か?」を理解するために、よく対比される「ウォーターフォール(以下WF)」と対比しながら説明してくれる一冊です。
読む上での注意点
この本を監修している企業はITコンサルタント事業の企業でWF開発をしている企業にAGを導入した経験を元に書かれております。そのため比較的WF開発の内容が多めになっております。その分AGへの理解が深まるという点もあるかと思いますが、AG開発をしている自社開発企業のエピソードではないため注意していただければと思います。
どちらかというとエンジニアよりマネージャー向けの本かもしれないです。
AG開発についての理解の変化
AG開発に関して、読む前まで私は小さく進めながら試行錯誤とリリースを繰り返しながら進めていくものと考えておりました。その反面仕様が決まっていない状態で設計することが多く、PMとエンジニアの役割分担が難しいなぁとも感じたりしていました。
読んだあと改めて考えると今までの理解はあながち間違ってないことを感じました。そしてAG開発自体型が確定しているものではなく、企業風土や担当するPMによって変化するものであると思いました。
この「型が決まっていない」点がAG開発の最大の強みでもあるかなと思います。エンジニアとしてAG開発に携わる際は、過去や型にとらわれず案件ごとにベストな方法は何か?を考えチーム全体で最適の形に常に変化させていくことが大事であると感じました!
極端な考え、例えば「AG=ドキュメントは作らない」「WF=ドキュメントをしっかり作る」といった考えはあまり持たないほうがいいと思いました。
まとめ
AG開発に関しての理解が深まった一冊でした。
そして技術と同じく常にアップデートをかけていかないといけないなとも思いました。アップデートに追いついていかないと企業にとってプラスの存在でいれないかもしれないので、動向をキャッチアップしていこうと思いました。
正解がないのがAGのいいところなので、プロダクトにとってベストの形を常に求めていきたいと思います!
AG・WFの知識に自信がない方の初心者本としてはおすすめなので、よければ読んでみてください。

memcachedに入門してみた
今回は、memcachedについてまとめてみようと思います。
弊社サービスでも採用されているのですが、触る機会があまりなく中身もわからなかったため今回まとめてます!
読み方は「メムキャッシュディー」と読むみたいです。間違っていたら教えてくださいmm
memcachedとは
memory cache daemonの略称になります。
分散メモリキャッシュシステムを構築することができるキャッシュサーバーになります。
メモリ上にデータを保存し、key-value-store方式でデータを保存するNoSQLに分類されるサーバーです。格納できるデータはstring型のみとなっています。
特徴
- データの読み込み・書き込み速度が速い
メモリ上にデータを保存するためデータの読み込み・書き込み速度が速いです。メモリ上で管理するため再起動するとデータはリセットされてしまいます。そのため消えても問題ないデータを保存することに向いています。
設定した容量を超えると、利用されていないキャッシュから削除されていきます。(LastRecentlyUsed)
- RDSの負担軽減
サーバーのメインメモリ上にファイルやデータベースの内容を一時保存して、高速に読み出すために使用されます。
またRDSと連携してクエリの実行結果を一時的に保存するために使用されたりもします。
RDSと組み合わせることでRDSの読み込み負担を軽減も期待できます。
- マルチスレッドで動作
マルチスレッドで動作するため、CPUのコア数を上げるとパフォーマンスも上がります。
- Redisとの比較
redisほど使えるコマンドが多くなく、シンプルかつスピード重視が特徴です。
Redisとmemcachedの比較
1. 永続化
redisはデータベースであるため、データの永続化が可能。
memcachedはキャッシュであるためデータの永続化は不可能。
2. スピード
redisはデータベースであるため、スピードは重視されていない。
memcachedはキャッシュであるため、スピードが重視されている。
3. データの種類
redisはList型Set型等複雑なデータ型が使用できる。
memcachedはkey-value-store型のみとシンプルなデータ型のみ使用できる。
4. マルチスレッド対応
redisはマルチスレッド非対応。
memcachedはマルチスレッド対応。
Redis・memcached共にキャッシュを扱うためのものであるとの認識はあったものの、調べてみると特徴がそれぞれあり、同じキャッシュでも用途が異なるものであることが分かりました。
速度重視の時代なので、開発力がある程度ついたらキャッシュの知識も深めていきたいと思いました!
最後まで読んでいただきありがとうございました!
Amazon Auroraについてまとめてみる。
今回は、Amazon Auroraに関してまとめてみようと思います。
新規開発でAmazon Aurora Serverlessを使用するので、基本から改めてまとめてみようと思います。
Amazon Auroraとは
Amazon AuroraはAWSが開発したMySQLおよびPostgreSQLと互換性のあるクラウド向けRDBのことです。
従来のMySQLおよびPostgreSQLは、OSSで安価であるのがメリットの一つですが、一方で性能を十分なものにするには別途スキルが必要になります。こちらをカバーするため、性能面や拡張機能を充実させたものがAmazon Auroraです。
AmazonRDSとAuroraの違い
1. コスト面
- AmazonRDS: コスト低。
- Aurora: (RDSに比べると)かかる傾向にある。
2. データベースエンジン
- AmazonRDS: MySQL・PostgreSQL・Oracle等多くのエンジンを選択可能。
- Aurora: MySQL・PostgreSQLのみ。
3. データベースバージョン
- AmazonRDS: あらゆるバージョンを選択できる。
- Aurora: 選択できるバージョンが限定されている。
(例)PostgreSQLは10・11・12・13・14のみ。
Auroraのアーキテクチャ
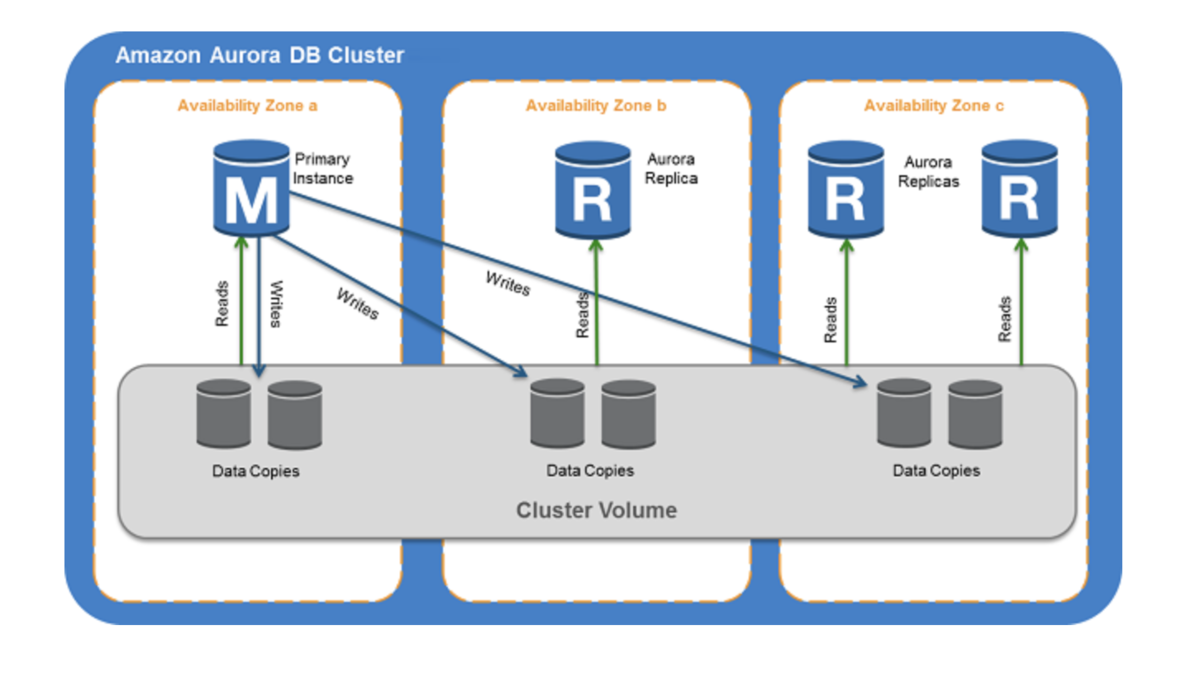
Auroraはクラスタという単位で構成されています。
クラスタは、1つ以上のDBサーバーで構成されるインスタンス層とデータを管理するストレージ層で構成されています。
データを保存するストレージ層は2.3AZにわたりコピーされるため障害が起きた際もデータベースの稼働に影響が出ないようになっています。
Auroraの特徴
1. バックトラック
より高速にデータベースの状態をリカバリする機能で、データを巻き戻したり進めたりすることができます。
2. クラスタキャッシュ管理
プライマリインスタンスが持っているキャッシュを特定のAuroraレプリカと共有することができる機能。
障害発生でフェールオーバーが行われた際に、キャッシュがフェールオーバーされないと一時的にDBの処理能力が下がってしまいます。クラスタキャッシュ管理を使用することで、フェールオーバー時のDB処理能力を抑えることが可能となります。
3. 並行クエリ
インスタンス層が実行するクエリ実行等の処理をストレージ層のリソースにオフロードして実行させる機能で、クエリの実行高速化が実現できます。
4. マルチマスター
従来のRDSはシングルマスター構成だが、Auroraは複数のプライマリDBを使用することができます。
よって片方のプライマリDBで障害が発生しても、もう片方のプライマリDBで継続的な書き込みができます。
特徴はまだたくさんあるのですが長くなってしまうため、一部のみの紹介とさせてください。
AmazonRDSかAuroraかの判断基準
1. AmazonRDSを選ぶ理由
- 最新バージョンを使用したい。
- Auroraでは利用できないサービスを利用したい。
2. Auroraを選ぶ理由
- Aurora独自の機能を使用したい。
- 運用面・性能面で最適化されたサービスを利用したい。
- 信頼性のあるサービスを利用したい。
Auroraについて改めてまとめてみました。
一つの記事にまとめようとするともっと大きくなってしまうため、一つ一つの機能にフォーカスしてまとめてみようと思います。
最後まで読んでいただきありがとうございました。
2023年のマンダラチャートを作成してみました!
みなさんこんにちは。たいきゅんです。
2023年も引き続きよろしくお願いいたします。
今年はさらなる飛躍のために目標設定から入っていこうと思います
マンダラチャートを導入。
目標設定で有名なマンダラチャートを採用してみました。
大谷選手が高校生時代に作成したものが有名ですね。
詳細はググっていただければと思いますが、真ん中に達成したい目標を設定したのち、それを達成するための目標をマンダラ状に作成していく目標設定方法です。
初めて作成したのですが見た目がすっきりしていて個人的にも満足しています。
作成したマップがこちら
こんな感じになりました。
サウナの目標は急がず見つかったら再度アップデートしようと思います。
目標の中でも特にストレッチな目標を赤色で記載してみました。
マップに関して改めて記載
今年も積み上げていくことを大事に一年間進めていこうと思っています。
目標について改めて考えてみると、常に考えていないと浮かばないものだなと感じました。
今年は目標を考える時間を多く、毎月FBをしてこの目標を達成することを大切に進んでいきます。
皆さんも目標を立てつつ今年を進めていくのはいかがでしょうか?
最後まで読んで頂きありがとうございました。